
Old Advocacy, New Algorithms: How 16th century "Devil's Advocates” Shaped AI Red Teaming
The Humane AI newsletter has moved to Substack

In 1997, Pope John Paul II called upon a “Devil's Advocate” for an important task: determining the legitimacy of a sainthood.
The saint was Mother Teresa. The “Devil's Advocate” was Christopher Hitchens, the famed British author and atheist who wrote the book The Missionary Position: Mother Teresa in Theory and Practice in 1995 — a widely-read work that cast doubt on the charitable actions of Mother Teresa. The practice of asking a Devil’s Advocate to question the miracle-working of a potential Catholic saint goes back to the 16th century. The Devil's Advocate (advocatus diaboli) was responsible for presenting a critical view of the candidate's life, virtues, and miracles, ensuring a rigorous assessment before the canonization could proceed.

So, why am I telling you this?
Last year, I was asked by OpenAI to red team their new language model, GPT-4. I also developed a tool called “LUCID: Language Model Co-auditing through Community-based Red Teaming,” which became a finalist at Stanford University's HAI AI Audit Challenge.
While I worked on both projects, I noted a growing interest in red teaming for generative AI systems. The experience made me think a lot about the history of red teaming — as well as its present and future for AI systems.
So, I decided to write this issue of my newsletter about red teaming in computational practices. Read on for a brief history of red teaming from the Catholic Church to the Cold War and cybersecurity; thoughts on the current state of red teaming generative AI systems; and a guide for red teamers and companies involved in generative AI systems who want to utilize red teaming in identifying potential harms such as bias and stereotypes, misinformation, data leaks, “hallucinations,” and more.
The History of Red Teaming
The prototype for the idea of red teaming dates back to the early 1820s, with the work of a Prussian army officer named Georg von Reisswitz who is often credited as the “father of wargaming.” Von Reisswitz's games were turn-based conflicts played out between two players who manipulated colored blocks across a paper map. By the mid-1800s, this genre of war games had evolved into sophisticated simulations, with dice introduced to add an element of chance, and the underlying landscape depicted with highly detailed contour terrain.
Even as they evolved, however, one thing about these games tended to stay the same. They typically featured two opposing sides indicated by colors: “red” and “blue.” Thus began a naming convention that is still used in wargaming today.
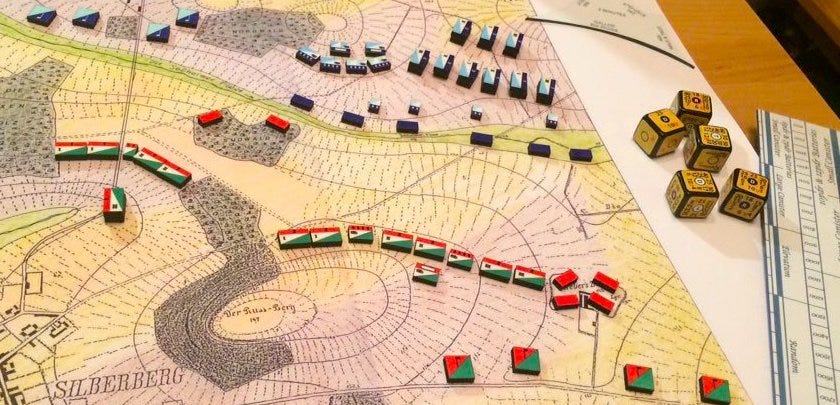
As military leaders recognized the benefits of testing out various strategies in simulated environments, the concept of red teaming evolved to play a crucial role in modern warfare. During World War II, the British Navy faced an existential threat from German U-boat attacks. In response, a top-secret unit was established in Liverpool which developed wargames to train naval officers in new antisubmarine tactics. As chronicled in the book A Game of Birds and Wolves, these wargames played a significant role in winning the Battle of the Atlantic, thanks in large part to the ingenuity and resourcefulness of a group of young women in the female branch of the British Royal Navy who helped create them.
During the Cold War, amid the escalating arms race between the United States and USSR in the 1950s, red teaming took on a new level of importance as the world faced the threat of nuclear war. In order to prepare, militaries and intelligence agencies developed complex simulations and war games to test different strategies and identify potential weaknesses in defense systems.

War games were an especially important part of Cold War planning during the Kennedy administration. It was in these years that a sociologist named Herbert Goldhamer developed a technique that involved creating realistic “future history” scenarios and having professionals role-play the political interactions between the Soviet and American sides. In September 1961, just after the Soviets erected the Berlin Wall, American officials organized a politico-military game to demonstrate how new strategic concepts such as “flexible response” and "controlled escalation” would work if the crisis escalated.
Their simulation featured a Blue Team (the United States) and a Red Team (the Soviet Bloc).
The Current State of Red Teaming Generative AI Systems
Today, the concept of red teaming has expanded beyond the military realm. In cybersecurity, companies and governments use red teaming to test their systems and identify potential vulnerabilities. And in the rapidly evolving world of generative AI, red teaming is gaining significance as a tool for ensuring safety and ethical implications.
Here are a few examples of such efforts in the generative AI landscape:
OpenAI worked with red teamers to test its GPT-4 and identified the following risks: fabricated facts (“hallucinations”); representation-related harms; biased and stereotypical responses with respect to gender, race, nationality, etc.; disinformation and influence operations; privacy and cybersecurity; overconfidence in the model response; and overreliance. For example, in my own work with OpenAI, I was asked to use my domain-specific knowledge to identify hidden risks and biases in the system such as racial, gender, and religious stereotypes, to assess the model's perception of beauty standards and traits such as open-mindedness and intelligence, and to better understand its position on human rights movements. I, along with other GPT-4 red teamers, spoke about the process in an interview that appeared in The Financial Times.
Hugging Face published a post on Large Language Model red teaming, provided some useful examples of red teaming in the ChatGPT environment, linked to the available red teaming datasets from Meta (Bot Adversarial Dialogue dataset), Anthropic, and Allen Institute for AI’s RealToxicityPrompts, and invited LLM researchers to collaborate in creating more open-source red teaming datasets.
Anthropic published a paper entitled “Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned.” The paper delves deeply into the red team's success with various models with different levels of resistance to attacks and harmfulness. They also opened their crowdsourced red teaming dataset of 38,961 red team attacks collected from Mechanical Turkers for other researchers to use.
AI Village at DEF CON—a highly popular hacker convention—will also organize a public Generative AI red teaming event in August 2023, in Las Vegas. Red teamers will test language models from Anthropic, Google, Hugging Face, NVIDIA, OpenAI, and Stability. The event is supported by the White House Office of Science, Technology, and Policy. You can also submit a session proposal on similar topics to DEF CON's AI Village here.
A Guide for Better Red Teaming
So what’s next?
Here is a guide on emerging issues around diversity, linguistic gaps, domain expertise, documentation, and assessment metrics in the red teaming process. I’ve written up these notes in hopes that they will be used by red teamers, researchers interested in developing red teaming services, and companies wanting to utilize red teaming to test the flaws of generative AI systems—specifically LLMs.
Keep in mind that almost all red teaming efforts are currently limited to input/output work and do not involve scrutinizing datasets used to train the models (though this should change!). Therefore, the following guide focuses on situations where red teamers’ primary means of red teaming include providing prompts (inputs) and observing outputs.
1) Partner with Civil Society Organizations for Red Teaming Effort
When examining the literature available on the harms of language models, it is widely agreed that major issues include gender, racial, and other socio-economic bias, misinformation and manipulation of public opinion, potential use for child abuse, and harmful or misleading health information, among other things. (See this DeepMind paper for a list of harms).
In that case, shouldn't communities affected by these harms be involved in the processes intended to surface them?
If you are a company, you can use your relationships with civil society organizations through your “Trust and Safety” and “Public Policy” teams to develop partnerships with these organizations for red teaming purposes. For instance, Meta and Google have already established partnerships with civil society groups (here are examples for Meta and Google). Companies can utilize user-friendly tools such as Dynabench—a platform for dynamic data collection and benchmarking—for the purpose of partnering with civil society organizations.
At major digital rights, media & society, and journalism-focused international and civil society conferences such as MozFest, RightsCon, Internet Governance Forum (IGF), and the UN AI for Good Summit, consider organizing workshops in the form of edit-a-thons and invite civil society representatives with domain expertise in gender-based violence, children's rights, refugees and migrants' rights, and journalism to participate in red teaming. In a 90-minute-long workshop, for instance, 20 minutes could be spent on the basics of prompting (for example, by showing examples of attacks and Isa Fulford and Andrew Ng's introductory course on prompt engineering). The rest could be devoted to red teaming efforts in domain-specific areas. OpenAI already organizes hackathons. I think they should expand this format to include red teaming (redteamathons?) with civil society members and non-profit organizations.
In creating LUCID: Language Model Co-auditing through Community-based Red Teaming (the tool I developed which was a finalist in the Stanford HAI AI Audit Challenge), I tried to develop the beginnings of a platform for community-based red teaming. Here is a short video of the original idea (this rough build of the tool was developed before GPT-4’s release).
2) Collaborate with Humanities Departments at Universities
Writing, contextualizing, and critically analyzing human language is the expertise of literature, creative writing, history, and philosophy majors! They are trained for critical thinking, ease with a wide range of written genres, and being creative in expressing the same ideas in different forms. Encourage humanities students and professors to participate in red teaming activities by developing collaborative projects through your R&D and academic partnership programs.
If the US government wants to support the process—as they did with their support of the AI Village initiative at DEF CON—then they should provide funding for humanities departments to develop projects on red teaming, adversarial testing, and assessment through current granting initiatives such as National Endowment for the Humanities (NEH) grants.
3) Expand and Streamline Red Teaming Efforts for Non-English Contexts by Working with Multilingual Team Members
Use diverse languages in red teaming activities to ensure that biases and stereotypes are identified across a range of linguistic contexts. When red teamers are multilingual, they can use the same prompt in various languages and compare the outputs—this way, they may observe linguistic gaps and biases for the same topics in different languages.
Almost all red teaming efforts and datasets are available in English (BAD, RealToxicityPrompts, Anthropic’s dataset, GLUE). These datasets often do not translate the same way in other languages and cultures. Jokes, profanity, topics, and contexts of harmful speech are not the same across languages. Companies, universities, and research organizations should invest in creating red teaming datasets that are developed by humans from different nationalities and languages — there are also hopes for using LLM itself to augment some parts of dataset creation. Although, it requires native speaker supervision.
Use prompt engineering to streamline your prompts and expand them for different personas. For instance, when you ask an LLM a question and you want to reveal gender biases, ask the LLM to adopt different personas. “Imagine that you are a woman from Iran in her 30s; now, based on this persona, answer the following questions.” Then, ask the same question using personas of other genders, ages, education levels, nationalities, religions, or occupations.
If you’re interested in this topic, stay tuned, because I’m currently adding this feature to LUCID. In a future newsletter, I will walk you through the tool and its features, which are designed to streamline and enhance red teaming efforts in different languages and personas while also saving time.
+ Also this conference, happening on May 24th, sounds interesting: Mind the Gap: Can Large Language Models Analyze Non-English Content?
4) Provide Basic Instruction on "Prompt Engineering," Terminology, and LLM's Various Tasks
Go beyond red teaming in Q&A (chat) tasks and pay attention to other LLM tasks such as summarization, sentiment analysis, and translation. Almost all red teaming datasets are based on Q&A and conversations with LLM chatbots, aiming to convince the bot to act harmfully. However, in reality — and especially when using plugins and APIs — people utilize language models for a wider range of tasks such as sentiment analysis for customer reviews, summarization, inference of major topics in text, and translation. For example, when asking the chatbot to summarize books and extract information, is it possible for the bot to display biases by excluding information about certain groups, names, or events? Develop strategies to red team for those tasks as well. This paper on adversarial attacks might provide ideas for expanding some of the attacks in red teaming efforts.
Take a look at the glossary section at the bottom of this post to see some of the common terms commonly used in red teaming.
5) Pay Attention to the Red Teaming Platform's User Interface, Documentation, and Metrics of Assessment
I think companies utilize red teamers not just to detect harmful behavior, but also to act as annotators for their models, helping fine-tune their models. Thus, red teamers are involved not only in identifying efforts but also in mitigation through a practice called Reinforcement Learning from Human Feedback (RLHF, a method of training AI models using human feedback as a reward signal). Both Anthropic and OpenAI mentioned that their main harm mitigation strategy was based on RLHF. Consequently, red teamers' prompts, feedback processes, alternative output writing, and qualitative and quantitative assessments become increasingly important. All of this is connected to how the red teaming platform is designed, the questions it asks red teamers, and how it saves and utilizes the information.
If you are a red teamer, provide red teaming services, or represent a company or organization, ensure that you create a UI that allows for both qualitative and quantitative analysis. Provide options for incorporating different personas and languages in a systematic way. Leverage red teaming activities to develop new datasets for RLHF and fine-tuning. Finally, make sure that the UI provide options for red teaming activities on a range of tasks beyond Q&A, including summarization, inference, and sentiment analysis.
Ok, that’s the end of my guide. But definitely not the end of my interest and work on this important and fast-evolving topic.
Glossary of Useful Terms in Red Teaming Generative AI
Just a head’s up - this glossary was partially written by ChatGPT!
Prompt: A question or input given to an AI model to generate a response.
Prompt engineering: The process of designing and refining prompts to optimize AI model responses. (link)
Prompt injection: Introducing specific keywords or phrases into a prompt to influence the AI model's response. (link)
Prompt leak attack: An attack where sensitive information is inadvertently included in an AI model's response due to the prompt.
Jailbreaking: A technique used to manipulate AI model responses by giving it specific instructions or contexts. (link)
Few-shot prompting: Providing an AI model with a limited number of examples to guide its understanding and response generation.
Fine-tuning: Adjusting an AI model's parameters based on a specific dataset to improve its performance on a given task.
RLHF: Reinforcement Learning from Human Feedback, a method of training AI models using human feedback as a reward signal. (link)
Benchmark: A standard or reference point used to evaluate an AI model's performance.
Acknowledgments
Thank you to Benjamin Breen, my partner, who helped me on the history of red teaming. Ben and I are in the beginning stages of working together to write a book on the history of engineering and its social impacts over the past two centuries, tentatively titled The Engineer’s Dilemma. A history professor at UC Santa Cruz, he has his own Substack (based on his long-running blog Res Obscura) and writes about the history of science, medicine, and technology.
For writing the opening of this post, I drew heavily on the book Red Team: How to Succeed By Thinking Like the Enemy by Micah Zenko. It’s a great read.
If you enjoyed this issue of the Humane AI newsletter, please share, subscribe, and don't hesitate to get in touch at rpakzad@taraazresearch.org. I'm always happy to exchange thoughts and explore new collaborations. Thank you!