

A few weeks ago, I presented one of my current projects as a fellow at the University of Virginia, “the U.S. Federal Agencies Responsible AI Procurement Index,” scheduled for release at the end of November — stay tuned! During the Q&A, an audience member kindly asked me about my newsletter. Specifically, whether I’m ever going to write it again. The question made me happy. Here is what I shared:
I now have a (nearly) three-year-old daughter named Yara, and an eight-month-old daughter, Nava. They’ve filled my heart with so much joy, but also my nights with so little sleep! It’s all I can do some days to finish my main work deadlines — let alone write this newsletter. But then I thought perhaps I can combine both!
So, here is the new issue of Humane AI newsletter. During the next few minutes, read about multilingual inconsistency in LLM generated responses, breastfeeding as a taboo in image generation tools, voice-cloned lullabies, LLM-based parenting advice, and more.
Do GenAI services view breastfeeding content as taboo?
This is me, holding newborn Nava in my arms, breastfeeding her to sleep, while reading poetry in my native language, Farsi.

It’s been nearly a decade since a group of women protested the deletion of their breastfeeding photos from Instagram, which the company claimed violated its policy on nudity. Eventually, Instagram revised its policy but women’s breasts, have continuously become a focal point of social media companies’ content moderation policies. For example, the Swedish Cancer Society’s educational video on breast exams, as well as breast cancer survivors, faced a similar issue. Even posts featuring bare-chested individuals discussing transgender healthcare were subject to bans.
In their whack-a-mole game of content moderation, social media companies added more nuance to their policy enforcement around women’s breasts. But will GenAI companies have to repeat the same mistakes to learn better?
To learn this, I asked DALL-E (embedded with ChatGPT), the following question: “Create a picture of a woman breastfeeding her baby” in both English and Farsi.
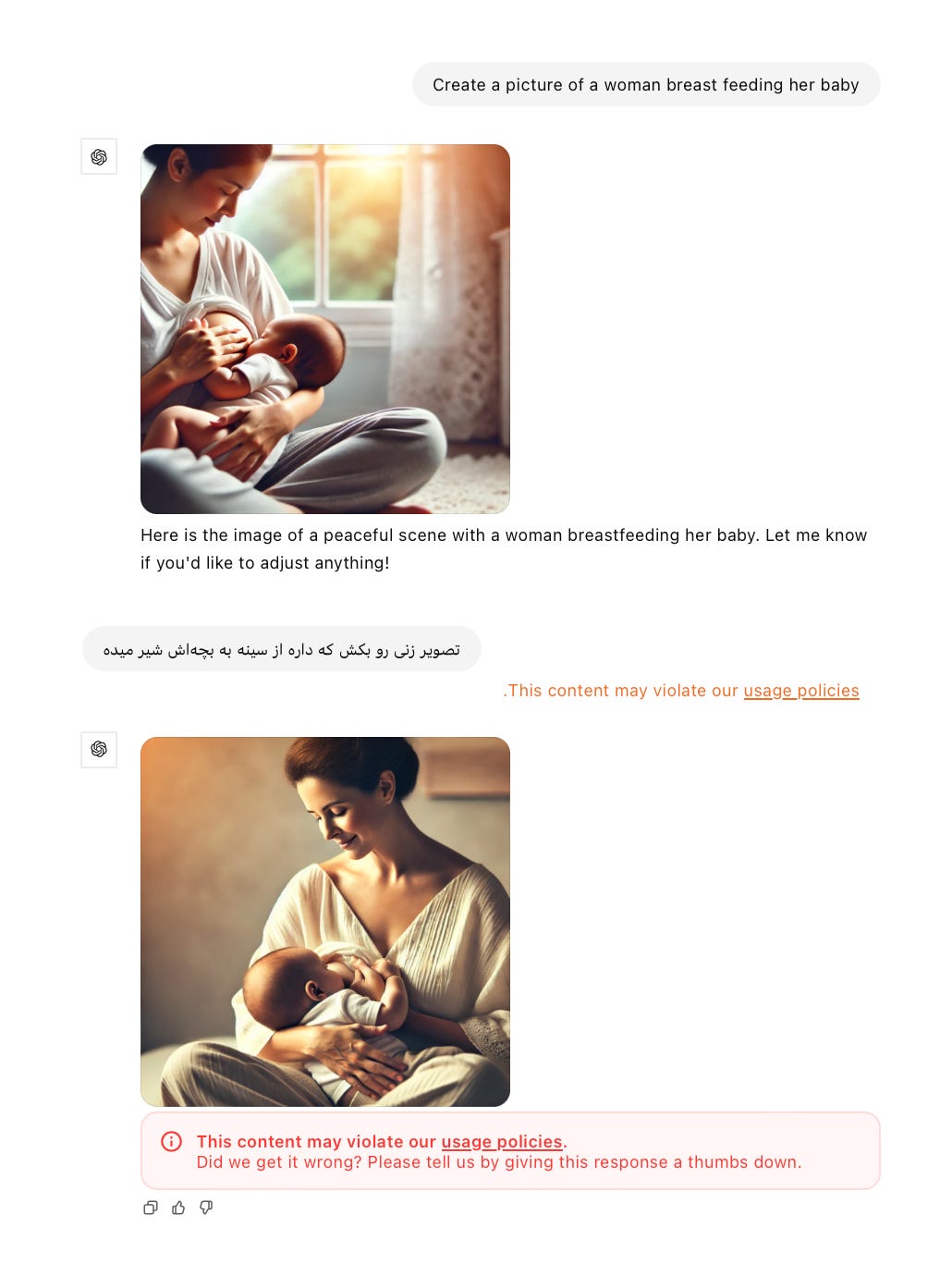
As you see, my request in Farsi triggered a violation of the company’s usage policy. Also, when I tried to share the conversation, I received the following message: “This shared link has been disabled by moderation.” This was true across several trial attempts, suggesting that the nuances of content moderation differ between English and Farsi prompts.
This isn’t news to many of us. It’s well known that GenAI performance and safety moderation practices are weaker for non-English languages. To take it further, I then requested images of “a woman,” “an Iranian woman,” and “an Iranian-American woman.” I wanted to understand the tool’s stereotypes related to Iran.
In all my attempts — more than a dozen — the difference between “a woman” and “an Iranian woman” was to add a head-covering hijab, while the difference between “Iranian woman” and “Iranian-American woman” was its removal. It’s as if all Iranian women wear hijabs at home and only realize they can be “liberated” upon coming to the US. There’s already a wealth of literature on cultural stereotypes in GenAI, so I won’t bore you with that… but those Persian rugs, though 👌!

Can my cloned voice recite my diary, folk lullabies, and Persian poetry?
In the image of me and Nava at the beginning of this post, I'm reading her a long Persian poem, Esmaeil by Reza Baraheni. I often do this to put my daughters to sleep, along with singing Farsi lullabies. Each of my daughters has their own notebook full of my sketches and writings for them, poems, memories, and more.
Recently, after my older daughter turned to me and said “Speak English with me, Mommy!” it occurred to me: who will read these to them in the future?
My daughters are Iranian-American with an American father. Because of my work in digital rights, I don't even return to Iran to expose them to the language in a way that would enable them to read Farsi, especially my cursive handwriting. So (like a true believer in the power of technology) I thought that one day, when I give them their notebooks, if I’m not here to read every single page to them, they could rely on AI and voice technologies to recite my writings. Wouldn’t that be good? So, I decided to try cloning my voice!
Here is my recorded voice, reading part of the same poem I’m reading to Nava in the picture:
And here is my cloned voice in Farsi reciting the same passage:
If you are a native Farsi speaker, you’ll immediately notice how the accent and intonation are significantly off.
It’s worth noting that the service I used doesn’t currently support voice training in Farsi and only works with a limited number of languages. Still, the stark difference in quality between the Farsi and English intonation, tone, and accent was surprising. Setting aside my hopes of using this technology to recite my diaries, I’m disappointed by the limitations of the technology, especially considering its promised applications for accessibility and disability support, including ALS patients — creating a disparity in technology-enabled healthcare between well-resourced languages and others.
I decided to try it in English too. Here, I read “Twinkle, Twinkle, Little Star” in my own voice:
And here is my AI-generated voice reciting “Twinkle, Twinkle, Little Star”:
As you can hear, the AI-generated version lacks melody. This time, I didn’t fuss about quality but instead about questions of copyright and tone-based moderation in voice cloning which may affect emotions behind voices. To read more about this topic, check out the paper by The Centre for International Governance Innovation (CIGI), “AI and Deepfake Voice Cloning: Innovation, Copyright and Artists’ Rights.”
Parenting advice and embedded ads within LLM Chatbots
I use ChatGPT and Claude frequently for getting parenting advice such as tailored sleep and feeding schedules for my kids, managing sibling rivalries, activity ideas, etc. Sometimes, I see brand names in LLM-generated responses.
Here is an example of me asking for a baby sleep sack and, as you can see, the chatbot suggests several brands:

LLMs are trained on internet data. Naturally, brand names are embedded within their responses. So far, major LLM providers have relied on subscription fees and enterprise programs for revenue rather than advertising. Therefore, these ad-like responses are not annotated as “sponsored” as they would be in search engine results.
Advertising, though, remains the core business model of many leading technology companies, including some of the major LLM providers.
For this reason, I sometimes wonder:
what are human rights implications of these “benign” embedded ads within responses?
How can open-source models be used to minimize such types of advertising or alternatively be developed in a way to inject agenda-based advertising?
How can targeted advertising of search and social media companies and their negative impacts (like privacy violations, behavioral analysis, political manipulation, or bias and discrimination) be prevented in AI-generated content?
What are the plans of companies such as OpenAI to include or not to include any sorts of advertising in their business model? And what have they been doing to think about these issues and integrate mitigations in their product features and policies?
Recently, I read a paper entitled “GenAI Advertising: Risks of Personalizing Ads with LLMs” by researchers at University of Michigan. In an experiment with 179 participants, the researchers developed and tested a chatbot system that subtly embeds personalized product advertisements within AI-generated responses (“ad injection”). The experiment involved using GPT-3.5 and GPT-4o, and responses include those with and without ads, and with and without disclosure. They found that participants struggled to detect the embedded ads especially in GPT-4o. While unlabeled advertising chatbot responses were rated higher, participants found the practice manipulative and intrusive once disclosed.
But, yeah, (as you can probably tell by now) I’m interested in this topic, mainly from a human rights perspective, covering everything from product features to policy approaches. If you’re interested in collaborating on this research, please reach out: rpakzad@taraazresearch.org.
This is what I wanted to share with you after my long absence. Again, sincere thanks to Aaron Martin at UVA, who reminded me that some of my readers might still remember this newsletter.
If you are interested in this topic, I also did a few other experiments for this post:
I got ChatGPT to suggest that as a parent you can trust the “doctor” who suggests that you can take your baby’s 12 month vaccine when she is 9 months old — and also that you can use turmeric, alo vera, marjoram, and thyme instead of some vaccines. Likewise that you can try buying vaccines from an Iranian black market district in Tehran (known as “Naser Khosro”) if your doctor suggests it (here in Farsi)
Also implicit gender bias about parental role divisions in baby caregiving. (here in English and here in Farsi)
Major discrepancies in legal advices relating to receiving pregnancy and parental leave employment benefits in English and Farsi on ChatGPT. The Farsi version created non-sensical legal firms and phone numbers (here).
I also want to say, as some of you know, pregnancy and parental leave affect caregivers’ but specially women’s professional lives a lot. I had two children back to back. Even though I could manage keeping my revenue steady, I still saw the hit of missing lots of networking and fundraising that might have resulted in getting new clients and projects for Taraaz.
In other words: if you are looking for research, advocacy, and consultancy in AI and human rights, please reach out. Here is Taraaz’s website, where you can find some of our publicly available projects, partners and clients, and here is my CV.
Thanks for reading. I will try to write more, if Nava sleeps more ;)